
说明
集群速度测试的目的是帮助各位朋友针对不同的计算体系选择集群上合适的计算资源,严格来说,计算量的大小应该是以【体系总电子数+体系真空层大小】进行评估,但是考虑到vasp软件使用者水平参差不齐,也为了使我们的测试结果简单易懂、方便参考,我们使用了【体系原子数+二维/三维材料】对计算量进行了简单的划分
这个测试不仅针对鸢算科技服务器集群上的硬件配置,我们也会不断收集其他服务器硬件配置使用VASP软件计算不同大小的体系的速度。如果您有不同于下文的硬件配置的服务器,欢迎下载我们的测试示例进行测试并联系我们补充到网站上
测试条件
由于大部分硬件都来自于朋友的帮助支持,我们无法对加速参数(NCORE、KPAR等)进行详尽的测试,只能要求测试时选择习惯上常用的加速参数,因此下面的部分测试结果并不能完全反应该硬件的真实性能
测试结果是不同大小体系使用VASP软件跑60个电子步的时间,以OUTCAR里的Elapsed time为准(使用命令grep Elapsed OUTCAR提取,单位为秒),计算时间越短,代表性能越强
硬件配置详情
| 配置 | 加速参数 | 来源 |
| 8×V100 (NVLINK) | KPAR=4, 8 | 苏州大学ganfisher |
| 2×V100 (NVLINK) | KPAR=2 | 鸢算科技弦月一号集群 |
| 4×P100 (PCIE) | KPAR=4 | 鸢算科技彩虹一号/弦月一号集群 |
| Intel Silver 4314 (32核, 主频2.4GHz) | NCORE=4 | 北京科技大学Count X |
| Intel Platinum 8259CL (48核,主频2.5GHz) | NCORE=6, 8 | 鸢算科技弦月一号集群 |
| Intel Platinum 8369B (64核,主频2.9GHz) | NCORE=1, 8, 16 | 辽宁石油化工大学万老师 |
| Intel Platinum 8375C (64核,主频2.9GHz) | NCORE=16 | 南京大学njuyao |
| 单路AMD EPYC 7K62 (48核, 主频2.6GHz) | NCORE=6, 8 | 武汉理工大学liangj |
| AMD EPYC 7542 (64核, 主频2.35GHz) | NCORE=8 | 并行科技 (沈阳理工大学田老师) |
| AMD EPYC 9554 (128核, 主频3.1GHz) | NCORE=16 | 郑州大学Flamingo |
测试结果
测速结果按照显卡、Intel CPU和AMD CPU类型分为浅绿色、浅蓝色和浅橙色
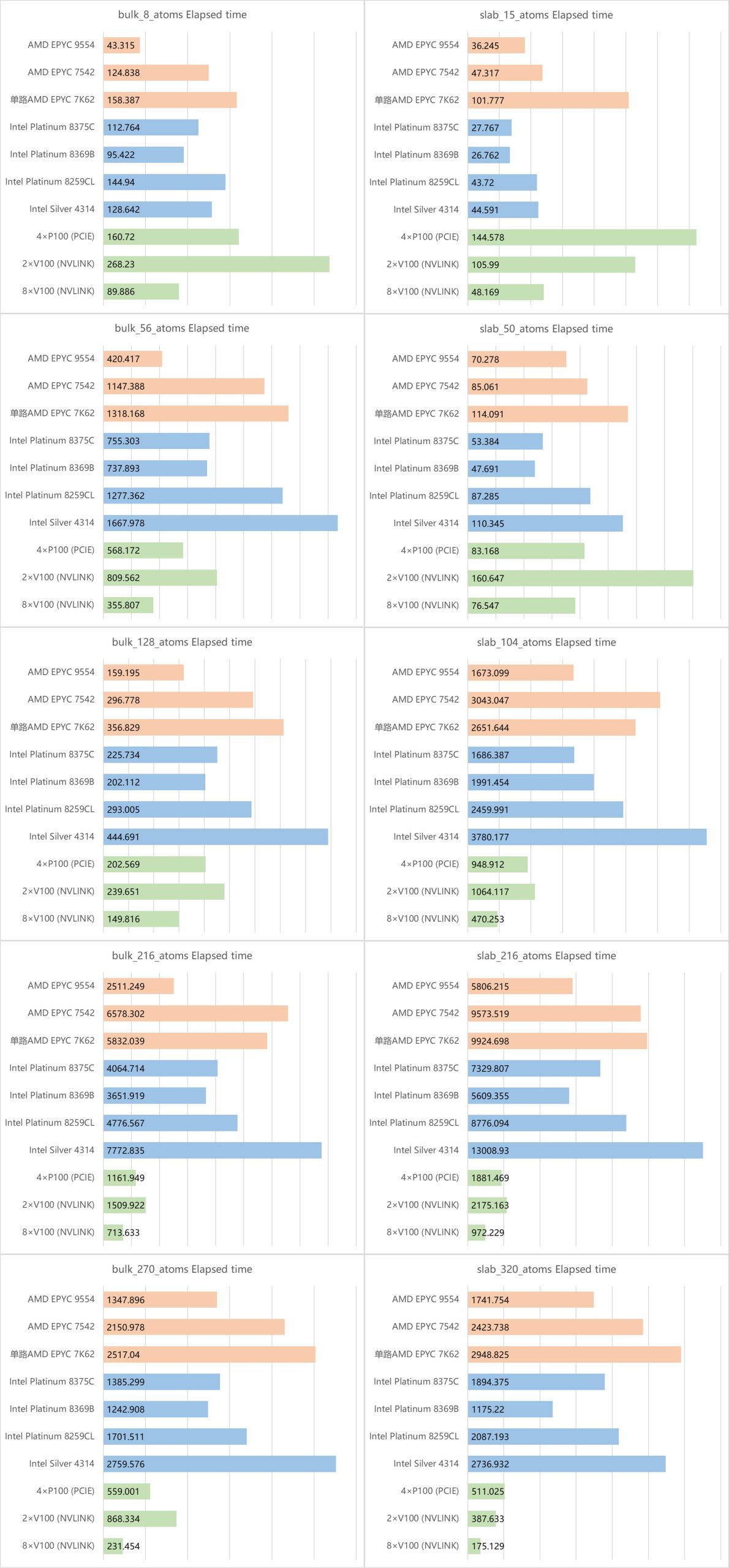
结果分析
此次测试体系分为了两种,分别为三维周期性材料(bulk)和二维周期性材料(slab,z轴真空层≥15埃)。另外,大家在参考计算量时,过渡态搜索计算量=插点数量×原子数
①slab和bulk相近原子数情况下,由于slab体系存在真空层,计算量显著增加
②虽然目前同价位下AMD比Intel的CPU核心数更多,主频也更高,但是AMD CPU的VASP计算速度并不占优势(尤其是bulk原子数>100体系和几乎所有slab体系中)。主要原因在于AMD CPU虽然核心数更多,但是多核并行效率不高,并且AMD CPU在编译VASP时需要特殊编译进行优化,甚至在主板BIOS设置中也需要调优,网上教程鱼龙混杂,对于大部分用户来说并不算友好
③在计算量较大的任务中(bulk体系原子数>150,slab体系原子数>100),P100和V100显卡计算速度是碾压AMD和Intel CPU的,尤其是大于两百个原子的体系,速度差距达到了5-10倍。
总结:通过这次测试可以看出做VASP计算时硬件合理搭配的重要性!硬件没有最贵或者最好,针对不同的计算,使用合适的计算资源才能既省时,又省钱!
鸢算科技弦月一号集群就是一个硬件配置搭配比较合理的集群,大家选择硬件时可以参考一下